
开始 Kohya

在此示例中,我们使用 Kohya: https://github.com/bmaltais/kohya_ss
使用 Kohya 生成图像标题
captions是在神经网络中对概念进行分类的东西,它产生图像特征和描述它的词语的相关性,它是生成式人工智能如何解释你的提示以产生输出。
Kohya 具有生成图像标题的功能,并将为每张图片创建一个文本文件。captions将构成神经网络将学习的内容的基础,尤其是你如何提示生成。
首先,使用 Kohya 为所有图片添加标题,然后我们可以描述可能具有特定元素的单个图片;我们可以添加到标题文件。
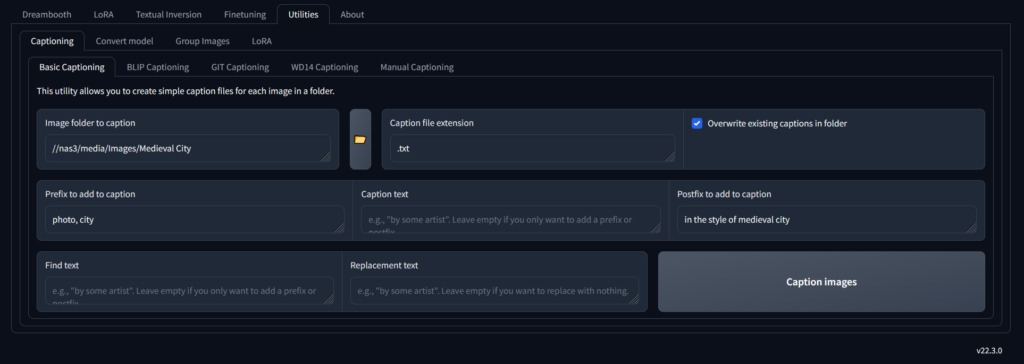
接下来会得到一个包含标签的文本文件。

使用 Kohya 进行训练
文件夹结构
设置 Kohya 所需的文件夹结构

将包含图像的文件夹移动到“img”文件夹中
NumberOfRepeats_Subject ClassTag
- 重复次数:与其他文件夹中的图像相比,此文件夹中的图像在训练权重中应“重复”多少次。此文件夹的内容在每轮将重复多少次
- subject:确定训练的东东
- ClassTag:标识事物的通用类别

配置训练运行
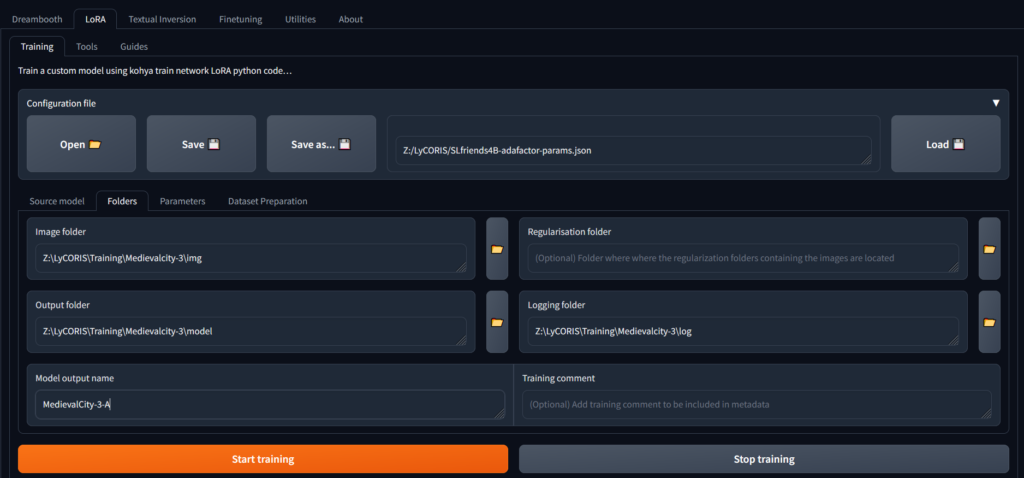
- json 文件链接(在“另存为”按钮旁边)包含上次的训练参数,我们将使用 Kohya UI 来调整我们想要的位置。
- “输入”文件夹是存储图像的文件夹
- 输出文件夹 - 输出模型的文件夹。
- 正则化文件夹。如果你试图确保你的训练不会失去标题的原始含义,一般放空
基本参数
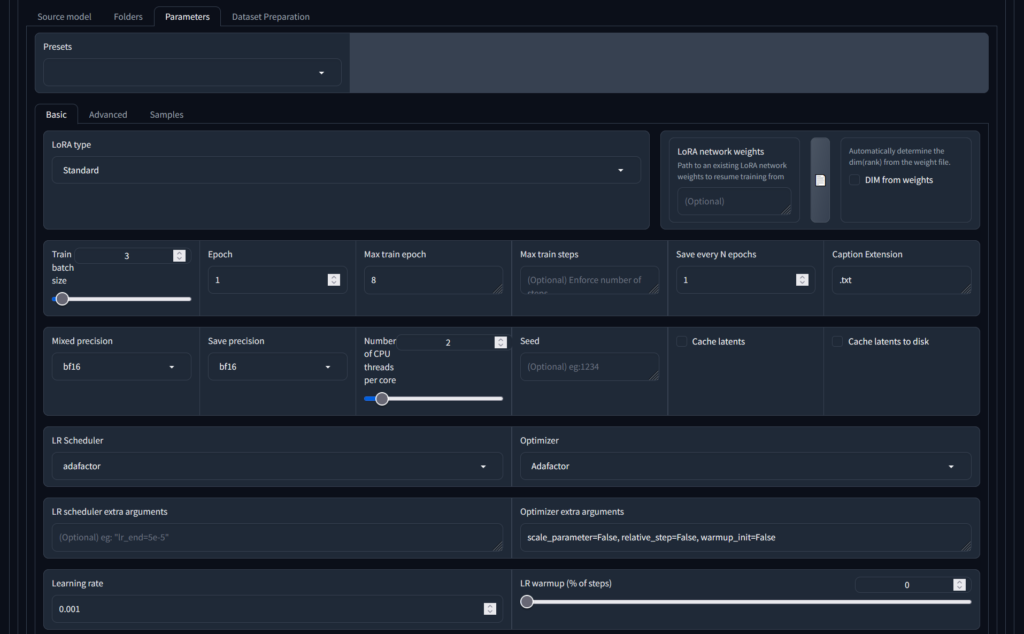
- LoRA 类型 - 建议使用“标准”。关于不同类型的讨论很多,但共识似乎开始指向“这并不重要,标准工作正常”的方向
- 训练批量大小 - 您希望一次处理多少张图像。该设置应主要取决于 GPU 的能力与运行训练所需的时间。批处理大小过高,您的 GPU 将采取非正常退出方式。批量大小太小(即选择 1:一次处理一张图像),训练需要更长的时间,并且会考验您的耐心。
- Epoch - 关于这个训练参数的讨论太多了,这似乎并不重要。将其保留为 1。
- 每 N 个纪元保存一次 - 建议在每个epochs后保留一个保存点,但这会占用磁盘空间。如果您愿意,这还将允许您使用不在训练运行结束时的保存点。
- 字幕扩展名 - 如果您为字幕文件使用了与“.txt”不同的扩展名,请使用可以在此处指定它。我的建议 - 坚持使用“.txt”:
- 混合精度/保存精度 - 指示 GPU 使用的浮点编码精度类型。对于大多数现代 GPU,请使用“bf16”(更多信息请见维基百科 - 请务必捐赠!
- LR(学习率)调度器和优化器。 建议使用 Adafactor。同样,有很多讨论,如果你有兴趣,请查一下。这些设置决定了学习率的变化时间表:学习率随时间变化的方式。
- 优化器额外参数 - 特定于 Adafactor 选择。我们发现这些设置效果更好(它们告诉 Adafactor 不要忽略下面的学习率参数)
- LR 周期和功率 - 可选
- 最大分辨率 - 您想要训练的分辨率以及您提供的图像将缩小到此分辨率。设置取决于您的基本型号。目前,高度和宽度的最大值为 768 是 Stable Diffusion 1.5 的最佳值。
- 停止文本编码器滑块 - 忽略,不起作用
- 启用存储桶 - 请确保选择此选项!这将允许您的图像源集具有不同的大小和分辨率。
- 文本编码器/Unet 学习率 - 如果您想优先考虑,请专注于学习字幕而不是图像。不适用于 Adafactor,因此在这种情况下忽略。
- 网络排名 - LoRA 会有多大。忽略滑块,输入数字。设置为 128 将为您提供大约 150Mb 的 LoRA。数字越大,神经元越多,神经网络中的通路越多,权重就越大。存储空间很便宜 - 至少 64
- 网络 alpha - 如果 alpha 和 rank 相同。它不能高于rank。低于rank的alpha 会降低 LoRA 的强度。保持 alpha 接近:与rank相同或略小于等级。我们将使用略低于rank的 alpha,并且考虑到我们拥有的图像数量和这些训练率,这有望提供一个 LoRA,我们可以在提示中以 .8 的权重使用。
训练

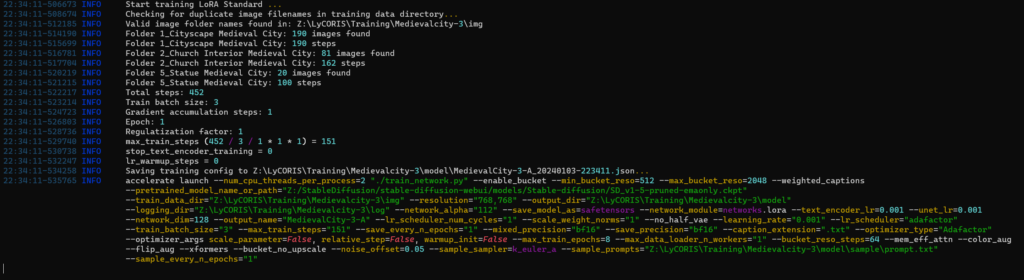
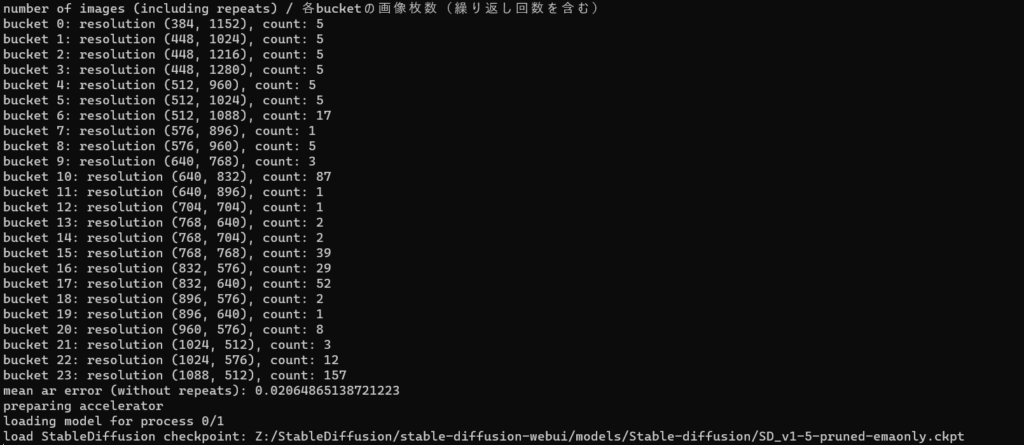
训练结果
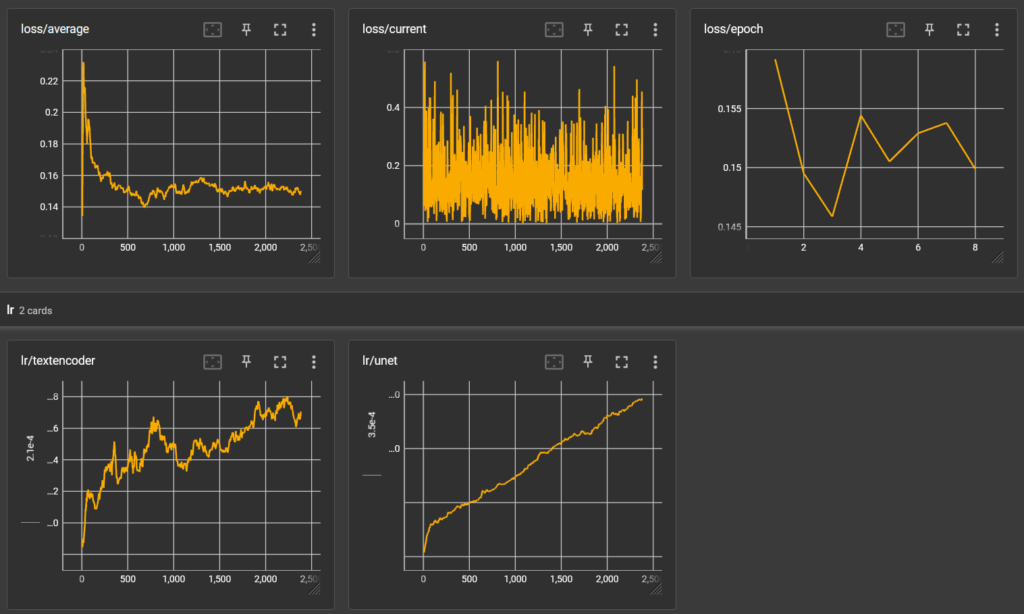
- Loss/average 趋于稳定
- Loss/epoch 有波动,所以需要更多epochs
- LR/textencoder 总体呈上升趋势,所以captions需要更多的训练次数
- LR/unet 一直在增加,所以需要增加更多训练集图片
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END














暂无评论内容